")
Web scraping is the process of extracting data from websites and structuring it into formats like CSV, XLS, XML, or SQL for further analysis and insights.
In this guide, I will explain how to perform web scraping using Python 3, along with the requests and BeautifulSoup4 libraries. These powerful Python libraries simplify the process: requests handles making HTTP requests to fetch web content, while BeautifulSoup is used to parse and extract data from HTML.
Requests Library
The requests library provides several key features:
- Session and cookies management
- Browser-style SSL verification
- Multipart file uploads
- Streaming downloads
Essentially, it supports all the functionalities required for modern web interactions. You can find more details in the official documentation: Requests Documentation.
BeautifulSoup (bs4)
The primary purpose of BeautifulSoup4 is to parse HTML content retrieved using the requests library. Since raw HTML needs to be processed to extract specific elements, BeautifulSoup simplifies this task.
For example, if we need to extract text from:
htmlCopyEdit<span id="my-text">Hello, world</span>
We can parse the HTML using BeautifulSoup and extract the text directly.Hellow, world” by Beautifulsoup(‘html_content’, ‘html.parser’).find(‘span’, id=’my-text’).get_text()
Documentation of Beautifulsoup4: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
This might look confusing but I will explain everything with an example. I will show you how to get themeforest top selling themes into a CSV file. Themeforest updates its weekly top selling themes here https://themeforest.net/top-sellers
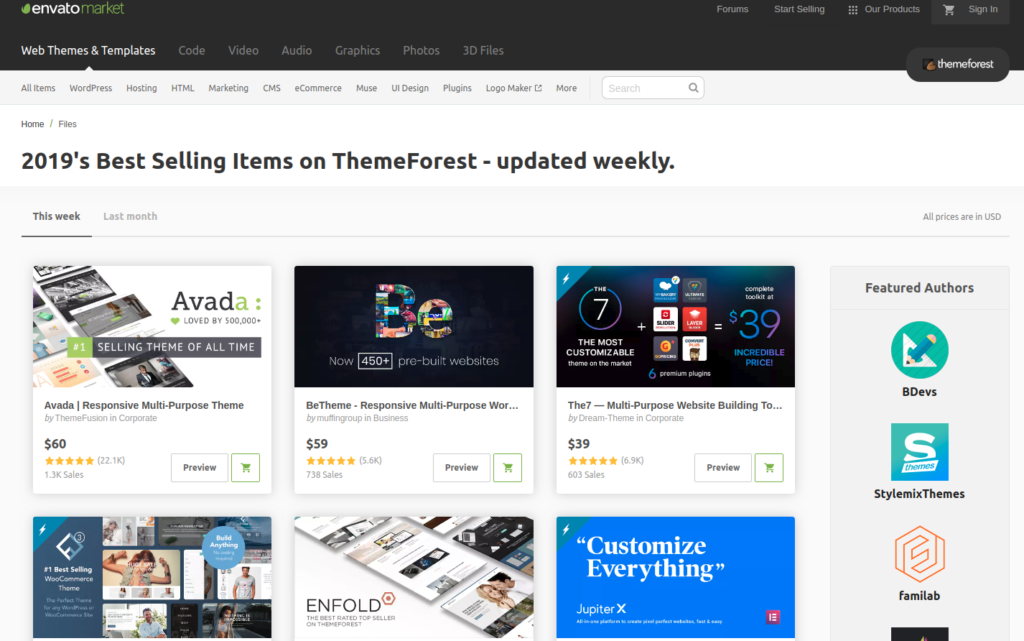
I had an idea about listing themeforest top selling theme and updating weekly on this blog. This could be tedious if done manually. So, I thought of using basic crawling techniques and automate a task and provide the same as an example for this article. It turned out to be very simple because all the data was already in JSON format. This makes easy for us to collect data and we might not need Beautifulsoup to parse. But I will use it anyway for the sake of an example.
Lets import required libraries first.
import requests import csv from bs4 import BeautifulSoup import re import json import datetime
Create and initialize CSV file with headers.
def __init__(self):
"""initialize csv file and columns"""
self.fieldnames = ['date', 'title', 'author', 'category', 'price', 'description',
'avg_star', 'total_review', 'total_sales', 'tags', 'link']
with open('output.csv', 'w') as csv_writer:
self.writer = csv.DictWriter(csv_writer, fieldnames=self.fieldnames)
self.writer.writeheader()
self.user_agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'
def crawl() is the main function where we send requests to the URL and collect data.
def crawl(self):
"""TODO: Docstring for crawl.
:returns: TODO
"""
response = requests.get('https://themeforest.net/top-sellers', headers={'User-Agent': self.user_agent})
content = response.text
soup = BeautifulSoup(content, 'html.parser')
script = soup.find('script', text=re.compile('window\.INITIAL_STATE=', re.I|re.M))
json_text = script.get_text()
json_text = re.search('INITIAL_STATE=(.*}}});', json_text, re.I|re.M)
if json_text:
json_text = json_text.group(1)
data = json.loads(json_text)
top_sellers = data['topSellersPage']['topSellers']['matches']
with open('output.csv', 'a') as csv_writer:
writer = csv.DictWriter(csv_writer, fieldnames=self.fieldnames)
for top in top_sellers:
row = dict()
row['date'] = datetime.datetime.today().strftime("%Y-%m-%d")
row['title'] = top['name']
row['author'] = top['author_username']
row['category'] = top['classification']
price = top['price_cents']
if price:
price = price/100
row['price'] = price
row['description'] = top['description'].strip()
row['avg_star'] = top['rating']['rating']
row['total_review'] = top['rating']['count']
row['total_sales'] = top['number_of_sales']
row['tags'] = ", ".join(top['tags'])
row['link'] = top['url']
writer.writerow(row)
Since required data is in <script> tag we can use Beautifulsoup to get only those script tag which has our data.
response = requests.get(‘https://themeforest.net/top-sellers’, headers={‘User-Agent’: self.user_agent})
content = response.text
soup = BeautifulSoup(content, ‘html.parser’)
script = soup.find(‘script’, text=re.compile(‘window\.INITIAL_STATE=’, re.I|re.M))

There are several script tag but our data is in the script tag containing “window\.INITIAL_STATE=” so we use Beautifulsoup with a regular expression to get that script tag.
Wrapping everything in a class,
import requests
import csv
from bs4 import BeautifulSoup
import re
import json
import datetime
class Webscraping(object):
"""Docstring for Webscraping. """
def __init__(self):
"""initialize csv file and columns"""
self.fieldnames = ['date', 'title', 'author', 'category', 'price', 'description',
'avg_star', 'total_review', 'total_sales', 'tags', 'link']
with open('output.csv', 'w') as csv_writer:
self.writer = csv.DictWriter(csv_writer, fieldnames=self.fieldnames)
self.writer.writeheader()
self.user_agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'
def crawl(self):
"""TODO: Docstring for crawl.
:returns: TODO
"""
response = requests.get('https://themeforest.net/top-sellers', headers={'User-Agent': self.user_agent})
content = response.text
soup = BeautifulSoup(content, 'html.parser')
script = soup.find('script', text=re.compile('window\.INITIAL_STATE=', re.I|re.M))
json_text = script.get_text()
json_text = re.search('INITIAL_STATE=(.*}}});', json_text, re.I|re.M)
if json_text:
json_text = json_text.group(1)
data = json.loads(json_text)
top_sellers = data['topSellersPage']['topSellers']['matches']
with open('output.csv', 'a') as csv_writer:
writer = csv.DictWriter(csv_writer, fieldnames=self.fieldnames)
for top in top_sellers:
row = dict()
row['date'] = datetime.datetime.today().strftime("%Y-%m-%d")
row['title'] = top['name']
row['author'] = top['author_username']
row['category'] = top['classification']
price = top['price_cents']
if price:
price = price/100
row['price'] = price
row['description'] = top['description'].strip()
row['avg_star'] = top['rating']['rating']
row['total_review'] = top['rating']['count']
row['total_sales'] = top['number_of_sales']
row['tags'] = ", ".join(top['tags'])
row['link'] = top['url']
writer.writerow(row)
scrape = Webscraping()
scrape.crawl()
Finally, all the details about the top-selling themes are saved in a CSV file. The JSON data contains more information than what is visible on the ThemeForest page, such as descriptions, tags, and more. I have included most of these details in the final dataset.
Please download the working example with the output CSV file here.
[download id=”158″]
Other Articles
")
")